Our mission at PBS is to educate, inspire, and entertain viewers like you. This north star has guided every decision we’ve made, even when it comes to our technology investments. We aren’t aiming to be the next Amazon Prime or Netflix – our goal is to provide amazing content and services to the public in the most cost-effective way possible. The solution can’t always be “let’s just launch a bigger instance” or “let’s just add a few read replicas.” Sometimes, the answer lies in what we can remove or streamline, rather than what we should add. After all, these are your dollars at work, and it’s something each and every one of us at PBS takes to heart, shaping our approach to problem-solving.
A mindset shift to fireproofing, not firefighting
My journey at PBS started back in 2009 when I first joined the organization as a contractor. At the time, my role was tech lead, supporting the team in maintaining and iterating on our existing systems. After a year, I moved on to other projects, but in 2014, the person who had been my boss during that initial stint reached out and asked if I’d be interested in taking on the role of Senior Director of Technical Operations.
My primary responsibility was firefighting – ensuring that our systems stayed up and running, and quickly addressing any issues that arose. It was a constant battle, as we struggled to keep pace with the growing demands on our infrastructure. I distinctly remember many late nights, huddled with my team, trying to diagnose and resolve problems before they impacted our viewers.
Personally, didn’t get the opportunity to watch many of our shows live because I was busy keeping an eye on our operational metrics and frankly, trying to keep things running so that our viewers could watch the newest content.
After a few years of that grind, I made the difficult decision to leave PBS in 2017. I was ready for something different and had been approached about a role at a for-profit company in which I would theoretically have a larger team and more of an ability to affect change. I quickly realized, however, that I had made a mistake. The mission-driven nature of PBS was something I deeply missed, and believe it or not, I missed working within the budgetary constraints of a non-profit. So, I started conversations with my former boss about returning, even though they had already backfilled my original role. He gave me the freedom to think through what I felt was missing in our organization and was hoping to work on. This became the role of Cloud Architect, focusing more on fireproofing our systems rather than just firefighting.
The key difference was that instead of just reacting to issues as they came up, I was proactively reworking our infrastructure to be more resilient, scalable, and cost-effective. This represented a significant mindset shift for me, and it also required close collaboration across our engineering, operations, and product teams. Together, we had to ensure our investments aligned with PBS’s mission - delivering exceptional content for viewers like you, while responsibly stewarding our limited resources.
Re-architecting for resilience
One of the early, recurring challenges we faced was scaling for major events, like the premieres of new documentaries or the start of new seasons for shows like Downton Abbey. These marquee programs would invariably drive massive spikes in traffic to our streaming platforms, and our initial EC2-based architecture struggled to keep up year after year. In many cases, we would experience “thundering herd” scenarios, for example: when a marketing email went out or people saw the “Visit pbs.org/masterpiece to learn more” at the end of an episode. All the while, we were adapting to ever-shifting release models for new content (day of, day after, and entire seasons available on day one).
We would find ourselves in frantic “firefighting” mode, rapidly spinning up new servers to handle the load, only to have the traffic subside and leave us with significant unused capacity. This cycle of scaling up and down reactively was both costly and stressful.
A perfect example of this was the premier of Ken Burns’ “The Vietnam War”. We knew we’d have increased traffic, but we didn’t anticipate the spikes we were seeing. At the time, Chef and OpsWorks were used to configure and deploy instances to handle the scale, but performance was sluggish. It took us some time to find several bottlenecks in our setup. Part of our confusion was that our monitors showed CPU usage, memory, and network were all nominal, so we couldn’t understand why our systems were behaving the way they were, so we just kept throwing more machines at the problem. It turns out there were arbitrary limitations on things like open file handlers, and the number of processes and threads our runtimes would spin up. Once we discovered and worked through that, we were able to handle more load with fewer instances, and we managed things much better.
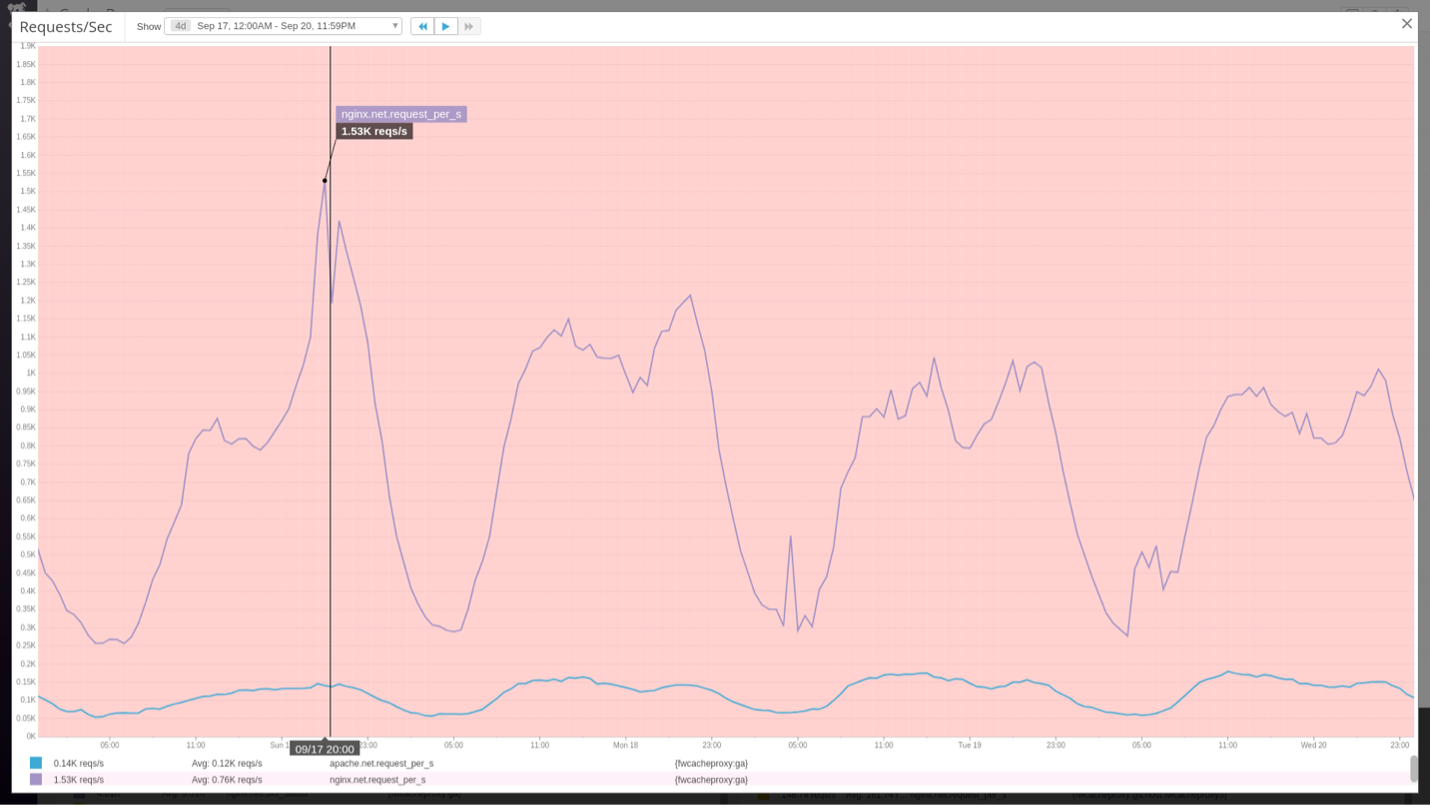
After the challenges faced during this premiere, where scaling issues led to long nights mitigating problems, we realized that we needed a more resilient and efficient approach. That’s when we started exploring elastic containers. Containerizing our platform and using Fargate to scale our infrastructure up and down rapidly helped us meet demand without the wasteful overhead of constantly running and underutilized servers. To put this into perspective, last year we were able to reduce our compute costs by 86% even as our compute usage and streaming traffic doubled.
While the benefits of the new containerized and serverless approach were clear, the transition itself required a significant cultural shift within the organization. I had to work closely with our product teams to help them understand the importance of performance and uptime as a feature, not just the new shiny button they were tasked with delivering. Changing the mindset from “firefighting” to “fireproofing” required constant communication and collaboration.
I couldn’t simply mandate technological changes – I had to bring our partners along on the journey, explaining the benefits and helping them see how it would make their jobs easier in the long run. It was a delicate balance, as I wanted to empower our teams to be agile and innovative, but I also needed to ensure that they were making decisions with the overall system in mind.
One of the key strategies I employed was to provide teams with a clear set of guardrails, rather than overly restrictive rules. I didn’t want to be the “permission police,” constantly approving every change. So, I did things like set up a pre-prod environment where our engineers could test and run experiments without consequences or creating Terraform modules that showcased the PBS way of doing things. My goal was to lead by example, and to automate away human error where possible. To make it easier for my engineers to understand the implications of their decisions, and then trusting them to make responsible choices.
For all of this to work, it also meant investing heavily in observability – because you can’t monitor what you don’t see. We built custom dashboards and reporting tools that gave teams visibility into their cloud resource consumption, latency metrics, and other key performance indicators. By surfacing this information in an accessible way, we were able to foster a culture of cost-consciousness and performance-mindedness.
The most impactful optimizations are often incremental
As we evolved our systems, we realized that simply focusing on the technological aspects wasn’t enough. We also needed to consider the broader environmental impact of our decisions. This has required a scrappy, iterative approach. We don’t have the luxury of ripping and replacing our entire infrastructure every few years. Instead, we’ve had to become masters of incremental improvement.
Whether it’s rightsizing our database instances, implementing more efficient video encoding, or automating our deletion processes, every optimization adds up to meaningful cost and carbon savings. And it’s not just about the bottom line - by being good stewards of our resources, we’re also able to reinvest those savings into creating even better content and services for our viewers.
One of the most impactful examples of this approach was our work to optimize the delivery of Sesame Street content. Back in 2009, when we were approached about featuring Sesame Street as a Google Doodle, our on-premises infrastructure was simply not equipped to handle the anticipated surge in traffic.

We made the decision to quickly migrate the Sesame Street website to AWS, and in the process, we were able to significantly improve the scalability and resilience of our content delivery systems. This was a pivotal moment for us, as it demonstrated the power of cloud-based architectures to help us rapidly adapt to changing demands.
Cultivating a culture of frugality
The story doesn’t end there. Over the years, we’ve continued to refine and optimize our content delivery system for an ever-growing catalog. One of the key areas we focused on was video encoding. We made the switch from AVC to a more modern codec, HEVC, which resulted in smaller file sizes, which means less data being stored, less data being streamed out over CloudFront and less data usage for our viewers. We also enabled variable bitrate encoding, which dynamically adjusts the video quality based on the viewer’s network conditions, ensuring an optimal viewing experience while reducing data consumption.
And we took a more intentional approach to how we encoded different types of content. For our kids programming, which makes up a significant portion of our catalog, we generally opted for lower bitrates. Many of our young viewers are accessing our content on lower-end devices with limited data plans, so we recognized that reducing the data usage for shows like Sesame Street could directly benefit those families by keeping their monthly phone bills down. We figured viewers aren’t going to notice a major difference between watching an episode of most children’s programming in 4K versus 720p, so the lower resolution was sufficient in those cases. However, for our more visually striking content, we prioritized higher bitrates and resolutions to deliver the best possible viewer experience. Some of this has been powered by AWS MediaConvert Automated ABR and we’ve also used tools like Mux Data to monitor viewer experience to ensure that we’re not causing any issues because of our changes.
These optimizations had a significant impact on our cloud costs. Prior to the codec switch and variable bitrate implementation, we had artificially limited the streaming quality on one of our streaming platforms to 720p as a cost-saving measure. But after realizing substantial savings on our CloudFront and S3 bills, we were able to open that back up and provide higher-quality 1080p streams to our viewers. By being proactive and iterative in our approach, we’ve been able to deliver an exceptional viewer experience while keeping our costs and environmental impact in check. These efforts have been an essential part of cultivating our culture of frugal architecting at PBS.
Cultivating this culture of frugal architecting hasn’t been easy, but it’s been essential to our success. We’ve had to overcome silos, educate teams, and constantly challenge our own assumptions. But by empowering our people to think creatively about cost and efficiency, we’ve been able to deliver an exceptional viewer experience while staying true to our values of responsible stewardship.
One of the key ways we’ve done this is by regularly sharing cost and performance insights across the organization. Whether it’s highlighting the impact of a new feature on our cloud bill or showcasing the benefits of a recent optimization, we make it a point to celebrate our wins and use them as opportunities to reinforce our frugal mindset.
We’ve also worked to break down the boundaries between our engineering and product teams, encouraging them to collaborate closely on technology decisions. Instead of just handing down mandates from on high, we’ve fostered a culture of open dialogue and mutual understanding. By helping our product colleagues see the value of performance, security, uptime and cost-efficiency as features, we’ve been able to align our roadmaps and make more informed choices about where to invest our resources.
Of course, the journey continues, and as technology evolves and viewer expectations change, we’ll need to constantly adapt and refine our systems. But I’m confident that our foundation of frugal architecting will serve us well, allowing us to keep focused on our mission of enriching the lives of viewers like you, no matter what challenges the future may hold.
Every single dollar matters to us
One of the most memorable moments in this journey came a few years ago, when we received a letter from a young viewer named Noah. Noah had sent us a dollar, along with a simple request: “I would like you to make a new show named Superheroes to the Rescue.” The kids team at PBS saw this as a heartwarming gesture, and within half an hour, they had put together a custom webpage thanking Noah and highlighting a few of our existing superhero-themed shows that we thought he might enjoy.

That moment encapsulates the spirit of what we’re trying to achieve at PBS. We’re not just building technology for technology’s sake - we’re here to serve our viewers, to inspire and educate them, and to do so in a way that is responsible and sustainable. Every decision we make, from the way we architect our systems to the way we manage our budgets, is guided by that core purpose.
And it’s not just about the big, flashy achievements, like scaling for a Ken Burns premiere or optimizing our Sesame Street delivery. It’s also about the smaller, incremental wins – the times when we’re able to save a few dollars here, reduce a bit of waste there, and reinvest that back into creating amazing content and experiences for our viewers.
Because at the end of the day, that’s what it’s all about. We’re not here to build the biggest, most powerful infrastructure in the world. We’re here to make a difference in the lives of people like Noah, and to do so in a way that is true to our values of frugality, sustainability, and mission-driven service.
So, as we continue to evolve and refine our systems, you can be sure that we’ll be guided by that same spirit of scrappy, incremental improvement. We’ll keep challenging ourselves, keep learning, and keep finding new ways to deliver exceptional value to our viewers – all while being responsible stewards of the resources entrusted to us.
After all, that’s what it means to be a frugal architect in the service of viewers like you.