Growing up, I thought my dad was cheap. I still remember our family driving long distances for family vacations — and I mean really long distances — to places like Florida or the Grand Tetons in Wyoming. My dad would wake the family up at the crack of dawn, get us to pile into the car along with some snacks and sandwiches, then drive for hours-on-end only stopping for bathroom breaks. The long hours spent in the car without stretching were sometimes grueling, but looking back, reducing stops and spending on hotels meant that we could do more at our final destination, like Disney World. My dad wasn’t cheap, he was frugal.
He also taught me the importance of doing things myself. He was a handyman, always fixing things around the house, doing oil changes and maintenance. Every time we’d fill the car with gas, we’d calculate miles per gallon from the previous tank (logging it in a notebook) — making sure things were running well. He was always on the hunt for the cheapest gas, but only if the cost to drive to the station wasn’t more than we’d save.
These were all calculated tradeoffs—and lessons that I’ve carried forward in my life and career. It probably also explains why I’m not a fan of cold sandwiches.
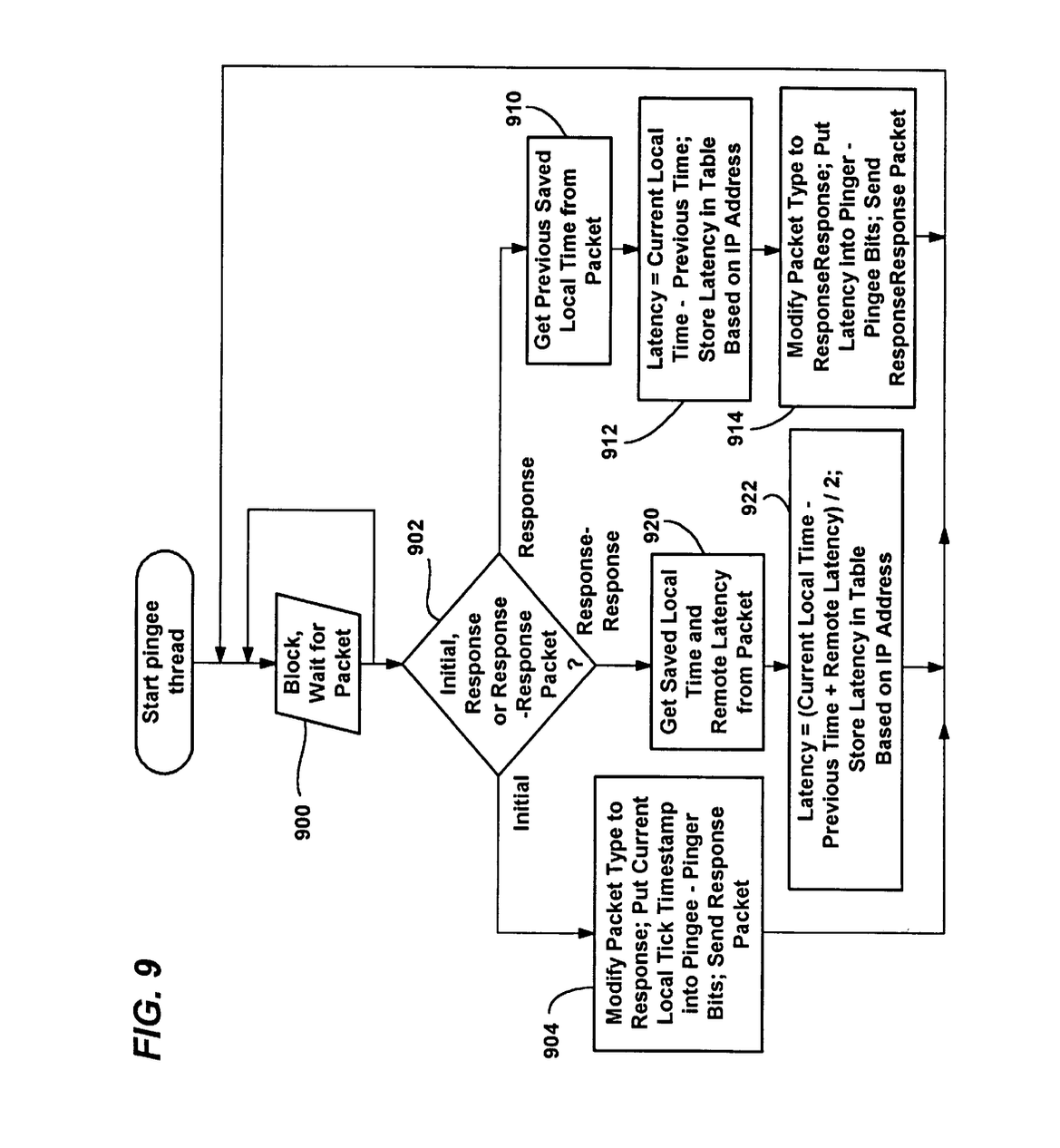
Early in my career, frugality played an important role while working at Microsoft on the Internet Gaming Zone. Adoption of the public Internet was just taking off and many customers accessed it via dial-up modems and AOL. The purpose of the Gaming Zone was to create an online community where individuals could come together and play games with each other over the Internet, whether it was turn-based card and board games, shooters (Quake), or real-time strategy games like Age of Empires. As the customer base grew, our datacenter capacity needs increased. Unlike today when you can easily autoscale instances in the cloud, we would need to go through a lengthy procurement process to acquire server hardware. This often meant that the team needed to be creative in getting the most out of the existing hardware, optimizing CPU, memory, and network usage down to the TCP buffer and socket limits. Additionally, because many of the customers were connected over dial-up, the team had to think about every bit, not just byte, sent over the wire to reduce latency and increase the amount of data that could be sent in as short a time as possible. For first person shooters and real time strategy games, a low latency connection to the player hosting the game was critical, and players often talked about their “ping”. Wanting to simulate a LAN party with low latency, I created a custom “ping” protocol which minimized bandwidth usage while helping to identify other players which had the lowest latency to a given customer, and thus enabling our players to have the best gaming experience possible.
Lessons in scale
A decade later, I was introduced to the Cloud when AWS only had the foundational services of EC2, S3, and SQS. I was a co-founder of FigurePrints, a company that used color 3D printers to generate custom figurines of World of Warcraft characters. As a small 4-person self-funded startup, we were quite conscious of our infrastructure costs. The operation ran on two used Dell servers and 4 mini desktops with early GPUs in them. One of the features of FigurePrints’ website was to render in real-time the customers’ World of Warcraft characters in different poses and equipment. For everyday traffic, the hardware setup worked well; however, every 3 months or so, the company would be featured on Blizzard’s World of Warcraft website. Given the 6 million players, this would cause a massive spike in traffic to the FigurePrints site, which the existing hardware would not be able to handle. As a small startup, it was not feasible for us to have additional hardware which would only be used a few days a quarter - not only hardware costs, but data center rack and power as well. I had just read about AWS, and the ability to “rent” compute by the hour seemed to be a perfect solution. After a bit of experimentation with EC2, I had c1 instances up and running with our custom model viewer software rendering images. After rendering these images, the servers would copy them to the webserver’s drive.
The first time FigurePrints was featured on the Blizzard website, things didn’t quite go as smoothly as hoped. The traffic spike was so large that there were not enough c1 instances to handle the load. Fortunately, it was easy to launch additional instances as autoscaling didn’t exist at the time. I added an additional instance, but it was quickly overloaded. I added another and it still wasn’t enough. Adding a third instance still wasn’t enough. I then added 6 instances at once, and we were finally able to handle the load. Once traffic stabilized, 2 of the instances were able to be removed. This was also the first time I learned a lesson (one which would need to be repeated in the future a few more times), that during capacity incidents it’s often best to not be too frugal, spend some extra money and scale out quickly to reduce customer impact, and then slowly scale back in. Days later when FigurePrints was no longer on the World of Warcraft website and traffic died down, I terminated the EC2 instances, reducing our cloud spend and only being charged a small fee for the EC2 AMI until we were featured again.
Because of time constraints, I only looked into leveraging EC2 at this time. In hindsight, this would have also been a perfect time to start leveraging purpose-built SQS instead of a queue implemented in a database. By leveraging highly-available SQS, it would have reduced IO on the database server and increased the system resiliency by removing a dependency on a single DB server. Additionally, FigurePrints was only using EC2 for rendering. If I would have moved the on-premise web server infrastructure to EC2, it would have reduced future data center expenditures, enabled faster adoption of newer hardware (via EC2 instance types) and AWS services, and provided high availability which would have avoided a multi-day outage caused by a fire in the garage of our datacenter provider.
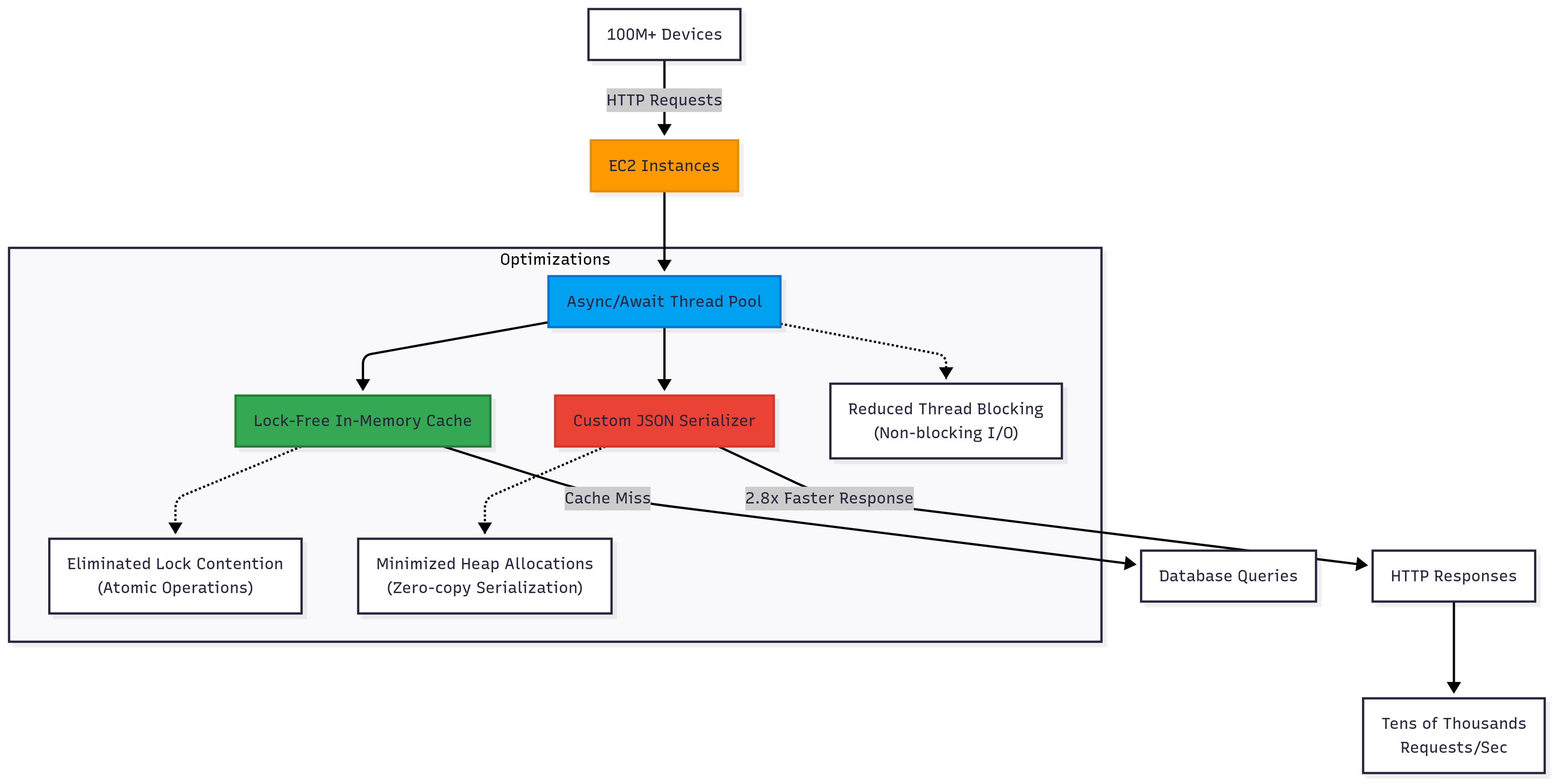
At FigurePrints I had learned the cloud, and by the time I found myself at Glympse (a location-sharing startup), I was using those learnings to architect, implement, and operate our entire backend in AWS. Being able to receive and share real-time location data securely was critical to the business, while also doing so in a cost-efficient manner to preserve the startup’s funds. Leveraging skills from previous roles, we knew we would need to optimize the servers, squeezing the most out of each EC2 instance. Much of the work done by these servers would not be compute intensive, as it was just recording and sharing GPS locations. This meant that memory was the default bottleneck, leaving a large amount of free (aka wasted) compute cycles. Thus to make the most out of the EC2 instances we were paying for, we wanted to use these CPU cycles too. To do so, we knew this meant minimizing the time threads were blocked by IO or synchronization access to memory via locks which would also increase the servers’ throughput. The team leveraged .NET’s new Async/Await paradigm, allowing an efficient use of thread pools while maintaining a readable code flow. Implementing lock-free in-memory caches also avoided lengthy delays waiting for common and popular database queries which would block the threads.
Having been in the games industry for a number of years, I had developed a habit of regularly profiling my code. I found it invaluable for validating assumptions about code execution and the behavior and cost of various function calls - especially ones in 3rd party libraries. After profiling the Glympse server code, I was surprised to see how much CPU was being spent serializing our data structures to JSON in the HTTP response. The default JSON serializer would create the HTTP response by repeatedly re-allocating strings and copying memory as values were serialized into the response. This re-allocation and copying caused significant heap allocations which in turn took locks blocking other threads, and then wasted CPU cycles by copying memory to enable appending of new data. I created a new custom serializer that significantly reduced the re-allocations and copies which resulted in a serializer which was 2.8x faster than any which were publicly available at the time. Combining these optimizations together, we were able to leverage more of our vCPUs, enabling a handful of servers to process tens of thousands of requests per second for an install base of over 100 million devices.
Think big, move fast
After Glympse, I moved to Zillow Group as their Cloud Architect, beginning their cloud journey and leading the move of its customer-facing web properties from datacenters to AWS. The initial migration was a “forklift” into the cloud, allowing Zillow to quickly take advantage of basic features such as high availability via multiple availability zones and rapid provisioning of new hardware (aka instances). Infrastructure as Code using Terraform was introduced from day one, creating standard and reproducible processes to provision infrastructure across environments. Given that one of Zillow’s core values is “Think Big, Move Fast”, it was important to allow engineers to experiment in AWS and try new features and ideas with minimal barriers. Teams could experiment with AWS in “sandbox” and development accounts, and then easily promote their code to more tightly controlled QA, staging, and production AWS accounts. As the teams experimented in the AWS, new cloud-native features were adopted, inspiring new services to be created in addition to the existing services being migrated from our datacenters. All of this lead to a month-over-month increase in cloud spend.
Besides the technical effort of moving from a data center to the cloud, there was also the financial shift from capital to operational expenditure accounting. Often teams deploying services to datacenters don’t think about cost, but in AWS you pay for what you provision per hour. Having tracked cloud spend closely at my previous two startups, I knew it would be important to do so at Zillow Group. Teams were beginning to create and leave unused infrastructure in the cloud. To better identify the spend increases, a multi-account and standardized tagging strategy was implemented. New accounts were assigned to business units and a set of well-known tags identifying the business unit, team, and service were created and exported as part of AWS Cost and Usage Reports (CUR). Using Redshift and Tableau to analyze this CUR data, I created a set of standard dashboards that could be consumed by anyone to view their spend and changes to it over time. These dashboards displayed AWS usage across major service categories and visually showed any spikes or change in spend over time. These were invaluable to quickly detecting and resolving unexpected usage that could have resulted in material spend increases. They were also sent out daily by email, and I often reviewed them while riding the train to work. Spikes in spend could easily be seen, questions could be quickly asked to responsible teams, and unexpected resource usage resolved in a timely manner. Though these dashboards were available for anyone to consume, it definitely took some time (years) to get others outside the Cloud Architecture team to routinely look at them.
Building Guardrails
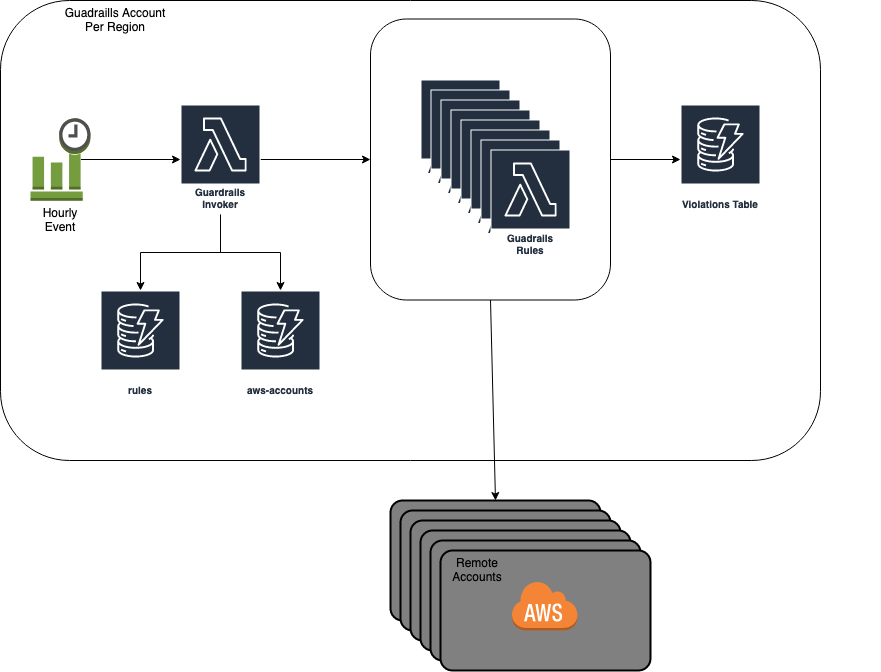
As time passed, the number of accounts and resources in AWS continued to increase at an exponential rate. I began looking for patterns to emerge and began thinking about automated solutions to reduce security risks, decrease spend, and improve efficiency. Inspired by a 2017 re:Invent talk by Amazon.com, my team created the Zillow Group Guardrails system. Guardrails is a flexible policy engine which leverages AWS Lambda functions to monitor usage across all of the enterprise’s accounts. Much like AWS Config, each policy rule reviews a specific AWS resource and then decides if it is compliant or not. For resources which are not compliant, the system creates a JIRA ticket describing the violation and assigns it to the owner of the resource. Once the violation is mitigated, the JIRA ticket automatically closes. The data and reports generated from the Guardrails system allowed my team and me to observe areas in which Zillow was doing well and other areas in which improvement was needed or had a potential cost savings opportunity.
The team has created nearly 200 rules to:
- Better secure the company’s AWS environments by eliminating IAM users with console access, removing access keys from root accounts, identifying IAM trusted with unknown 3rd party accounts, and reducing EC2 instances on the public Internet.
- Implement Best Practices: enabling S3 KMS Key Caching, adoption of GP3 EBS Volumes, Lambda runtimes reaching EOL, enabling MultiAZ and automatic failovers for ElastiCache, OpenSearch, and RDS and enabling S3 and DynamoDB Gateway Endpoints.
- Identifying Cost Savings Opportunities: S3 Lifecycle Policies (such as Intelligent Tiering), Cloudwatch Logs groups without expirations, DynamoDB table which would benefit from On-Demand usage, unused and over-provisioned resources spanning EC2, ElastiCache, ELB, RDS, and VPC Endpoints.
All eyes on spend
As Zillow Group’s usage and spend in the cloud increased it became more important to have additional people watching the spend on a daily basis. The Cloud Architecture team worked with various business leaders to get their teams to start reviewing the Tableau dashboards regularly. A recurring monthly “AWS Spend Review” meeting was scheduled, during which all the business leaders would come together to review their previous month’s spend against projected spend and discuss any variances. This brought spend front and center and created a forum to introduce and track cost savings initiatives across the company.
Recognizing that teams often deprioritized small cost-saving tickets and not always act quickly on cost-saving opportunities, the Cloud Architecture team created a tool, ACATS (AWS Cloud Architecture Tool Suite), to safely auto-remediate a subset of these violations in a non-destructive manner. Some of the issues that are auto-remediated include:
- Enabling an expiry period on all Cloudwatch Log Groups
- Enabling S3 Intelligent Tiering Lifecycle policies on buckets
- Downsizing Redis Clusters to smaller instance sizes
- Converting DynamoDB tables from provisioned capacity to on-demand
- Enabling S3 KMS Key caching
- Deleting EC2 Snapshots and AMIs using Recycle Bin
As Zillow Group worked to improve its sustainability posture, I began looking at Graviton. AWS’s new chipset uses up to 60% less energy while also reducing cost by 20%. Additionally, AWS made moving to Graviton for ElastiCache, RDS, and OpenSearch quite simple and something that could be done with zero downtime. These factors drove Zillow Group to require the use of Graviton for these managed services. My team and I leveraged our Guardrails system to identify the non-Graviton resources and then used ACATS to safely convert the resources to Graviton reducing spend, improving performance, and decreasing Zillow’s carbon footprint. To prevent these resources from being reverted from Graviton by out-of-date Terraform applies, the team enabled AWS Organization Service Control Policies (SCPs) that only allow the use of Graviton instances for these managed services.
Nerding out on networking
Alright, we’re going to get a little bit nerdy and dive into networking. While network design might seem vanilla compared to application development, it’s often where small decisions have the biggest impact on security and cost. And in AWS there are many options and services to optimize the network and reduce spend.
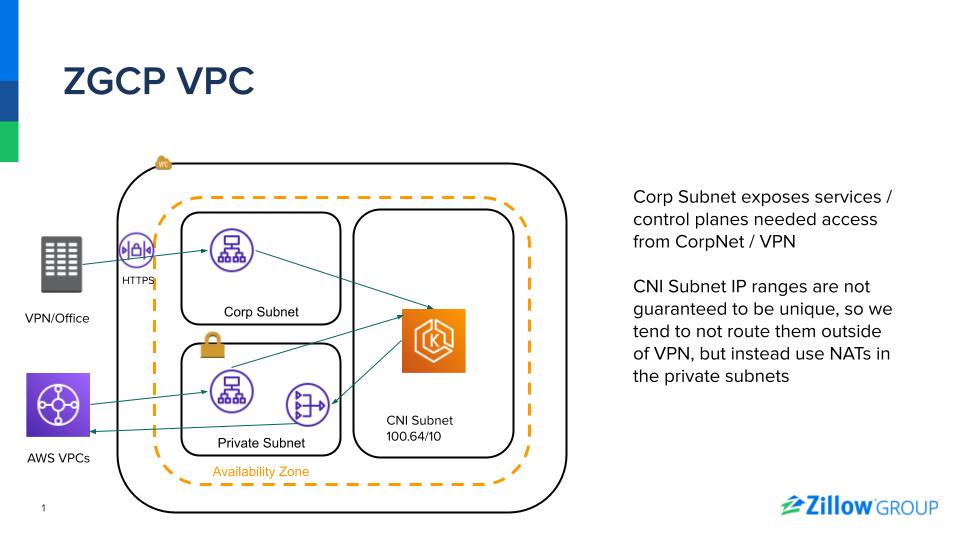
As the number of AWS accounts increased organically and through acquisitions, network complexity grew. Each of these VPCs had its own set of NATs which are used by EC2 instances in the VPCs to reach resources on the Internet, including AWS APIs. AWS managed NATs have two cost components: an hourly charge and a per-byte process fee. The hourly cost for the existence of all these NATs was adding up quickly with the large number of VPCs. And a large portion of the traffic going through the NATs was to AWS API. Though the AWS API traffic through the NATs could be reduced by adding VPC Endpoints to each VPC which would have also made the traffic mode secure, the hourly cost of each VPCE could not be justified by most of our accounts.
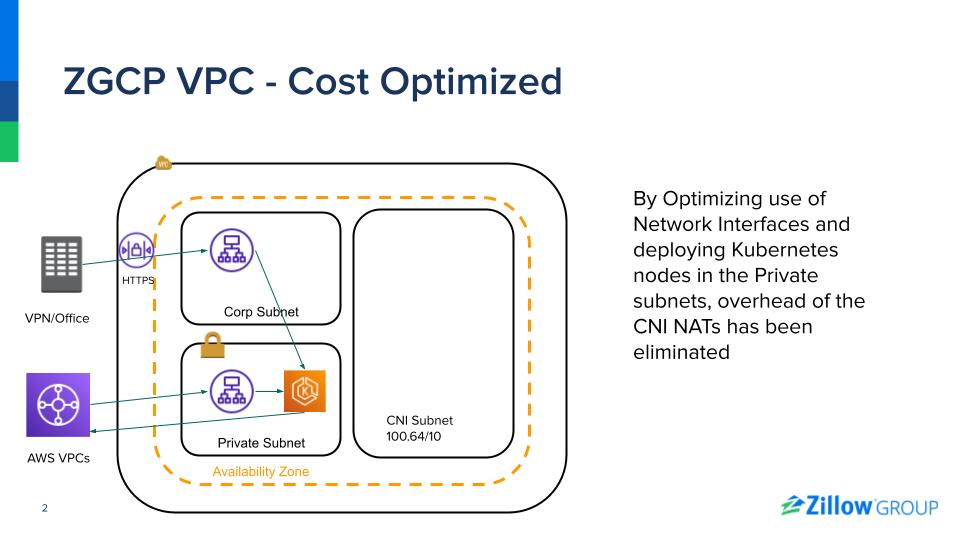
With the release of the AWS Transit Gateway (TGW), this all changed. I saw a way to increase network security and reduce hourly spend on NATs and Private Links. Dedicated egress VPCs with shared NATs were created and shared across the Transit Gateway allowing us to amortize the hourly cost of the NATs. Additionally, “AWS Service” VPCs were created that only contained VPC Endpoints connections to a vast number of AWS managed services. These new VPCs were then connected to existing VPCs across the company via our TGW and Route53 private hosted zones directly AWS bound traffic to these shared VPC Endpoints. This enabled traffic to AWS APIs to stay private (increase security) and avoid the NATs (reducing the per-byte process cost). Just like the shared NATs, we were able to amortize the hourly shared VPCE cost that previously were not able to justify. As an added benefit, the use of the shared NATs allowed the removal of public subnets from a majority of our VPCs, reducing the risk of infrastructure accidentally being created on the Internet.
However, adding this extra hop over the TGW is not free and adds additional data transfer cost. In high bandwidth use cases, this data transfer cost could exceed the hourly cost of a local endpoint or NAT. To identify and avoid unnecessary spend, I leveraged VPC Flow Logs and the CUR reports to track the usage of the shared NATs and VPC Endpoints on a per VPC basis. These dashboards highlight VPCs which it would be more cost-effective to have their own NATs or specific VPC endpoints. By routinely observing data flow and cost of the network, the network topology is incrementally tuned to be more cost-effective. A similar process was used to identify specific use cases where traditional VPC Peering would be significantly more cost-effective than peering over the TGW.
During Zillow Group’s adoption of Kubernetes and EKS, I was helping provision new accounts and VPCs for the clusters. Various engineers were concerned about Kubernetes’ consumption of IP addresses, so being frugal about routable IPv4 space, a decision was made to leverage large ranges from the 100.64/10 CIDR block for the pod networks and use private NATs to route the traffic to other VPCs. It was assumed that the vast majority of traffic would stay within a cluster. As our Kubernetes adoption grew, this assumption proved false. Rising costs were observed in Tableau Dashboard and it could be seen that the traffic passing through these private NATs was greater than expected. After analyzing the actual IP usage of the clusters, I realized that there were plenty of free, routable IPv4 addresses, and that the decision to use the non-routable IPv4 space was being overly frugal. After a few quick configuration changes to the subnets used by the EKS clusters, traffic stopped passing through the private NATs and monthly spend dropped by $15k.
Throughout my career, I’ve learned that frugally architecting systems is a skill developed over time; it doesn’t happen overnight. It requires a deep understanding of your systems, strong observability, and a keen eye for both obvious and subtle opportunities for improvement. Not every change is big, even small optimizations can add up to significant savings. The key is to create a culture where engineers are not only looking for optimization opportunities but are also empowered to implement them. At Zillow, we put this into practice by continually revisiting past decisions, using data to highlight opportunities, and creating tools to automate changes, all of which help us build efficient, effective, and sustainable systems that support our business goals and deliver value to our customers. As The Frugal Architect says, “There is always room for improvement… if we keep looking.”